created, $=dv.current().file.ctime & modified, =this.modified
tags: Computers
- lucerne, elasticsearch, postgres full text search
- MSSQL has full text search
The question that motivated this deep dive into BM25 was: can I compare the BM25 scores of documents across multiple queries to determine which query the document best matches?
At the most basic level, the goal of a full text search algorithm is to take a query and find the most relevant documents from a set of possibilities.
However, we don’t really know which documents are “relevant”, so the best we can do is guess. Specifically, we can rank documents based on the probability that they are relevant to the query. (This is called The Probability Ranking Principle.)
Components
- Query terms - if a search query is made up of multiple terms, BM25 will calculate a separate score for each term and then sum them up.
- Inverse Document Frequency - how rare is a given search term across the entire document collection? We want to boost the importance of rare words.
- Term Frequency in the document - how many times does a search term appear in a given document? Repetition of a term in a document might increase likelihood that a query term is related to the document.
- Document Length - how long is a given document, comparatively? Long docs might repeat the term more, by virtue of being longer.
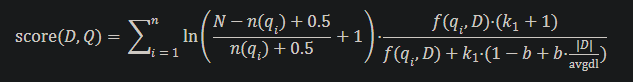
Probability Ranking Principle
If retrieved documents are ordered by decreasing probability of relevance on the data available, then the system’s effectiveness is the best that can be obtained for the data.
For any given query, we can assume that most documents are not going to be relevant. If we assume that the number of relevant documents is so small as to be negligible, we can just set those numbers to zero!
In general, BM25 scores cannot be directly compared. The algorithm does not produce a score from 0 to 1 that is easy to compare across systems, and it doesn’t even try to estimate the probability that a document is relevant. It only focuses on ranking documents within a certain collection in an order that approximates the probability of their relevance to the query. A higher BM25 score means the document is likely to be more relevant, but it isn’t the actual probability that it is relevant.
Hybrid
I’m concerned by the number of times I’ve heard, “oh, we can do RAG with retriever X, here’s the vector search query.” Yes, your retriever for a RAG flow should definitely support vector search, since that will let you find documents with similar semantics to a user’s query, but vector search is not enough. Your retriever should support a full hybrid search, meaning that it can perform both a vector search and full text search, then merge and re-rank the results. That will allow your RAG flow to find both semantically similar concepts, but also find exact matches like proper names, IDs, and numbers. via
It’s not purely vector space. It’s not like once the content is fetched, there is some BERT model that runs on all of it and puts it into a big gigantic vector database, which you retrieve from, it’s not like that. Because packing all the knowledge about a webpage into one vector space representation is very, very difficult. There’s like, first of all, vector embeddings are not magically working for text. It’s very hard to like understand what’s a relevant document to a particular query.