created, $=dv.current().file.ctime & modified, =this.modified
tags: AI Computers
rel: Survey of Computer Expert As Wizard Archetype
NOTE
Concerned this is too basic, but reading to explore Survey of Computer Expert As Wizard Archetype
Overview
AI coined by John McCarthy in the 1950s.
The word algorithm is cast about often these days, though it isn’t new; it’s a corruption of Al-Khwarizmi, referring to ninth-century Persian mathematician Muhammad ibn Musa al-Khwarizmi, whose primary gift to the world was the mathematics we call algebra.
Training a model is fundamentally different from programming. In programming, we implement the algorithm we want by instructing the computer step by step. In training, we use data to teach the model to adjust its parameters to produce correct output. There is no programming because, most of the time, we have no idea what the algorithm should be. We only know or believe a relationship exists between the inputs and the desired outputs. We hope a model can approximate that relationship well enough to be useful.
George Box - all models are wrong, some are useful.
Text uses MNIST dataset to train on numbers 0 to 9, omitting certain numbers (4, 7) and explains confusion matrices. Model mostly classified 4s as 9s and 7 were still called 3 and 9s.
Wolf and Husky classifier:
The model wasn’t paying attention to the dogs or the wolves. Instead, the model noticed that all the wolf training images had snow in the background, while none of the dog images contained snow. The model learned nothing about dogs and wolves but only about snow and no snow. Careless acceptance of the model’s behavior wouldn’t have revealed that fact, and the model might have been deployed only to fail in the wild.
Why Now? A History of AI
Two main camps of AI, Symbolic and Connectionism.
Symbolic - attempts to model intelligence by manipulating symbols and logical statements or associations.
Connectionism - attempts to model intelligence by building networks of simpler components.
Deep learning has been a point for connectionism.
Pre-1900s
Ancient Greeks had the myth of Talos, a giant robot meant to guard the Phoenician princess Europa. There was the Mechanical Turk, where a human inside manipulated the automaton. There were early attempts to understand thought as a mechanical process and produce a system capable of capturing such thoughts. Gottfriend Leibniz described it as an alphabet of thought.
19th century George Boole attempted to create a calculus of thought, resulting in Boolean algebra. His goal was “to investigate the fundamental laws of those operations of the mind by which reasoning is performed: to give expressions to them in the symbolic language of calculus.”
Babbage and Ada Lovelace with the Sketch of the Analytical Engine (1843).
The Analytical Engine has no pretension whatever to originate anything. It can do whatever we know how to order it to perform. It can follow analysis; but it has no power of anticipating any analytical relations or truths. Its province is to assist us in making available what we thought we were already acquainted with.
1900s to 1950s
Alan Turing with the Turing Machine and the Turing test.
Warren McCulloch and Walter Pitts wrote “A Logical Calculus of Ideas Immanent in Nervous Activity” which represents “nervous nets” (a collection of neurons) as logical statements in mathematics. You could argue this leads to our current Neural Network concept.
1950s to 1970s
1956 Datmouth Summer Research Project on AI workshop is regarded as the birthplace of AI and where the phrase AI was first used consistently. A year later Frank Rosenblatt created the Mark I Perception, the first widely recognized application of neural network.
NYT in 1958
The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence. Later perceptrons will be able to recognize people and call out their names and instantly translate speech in one language to speech and writing in another language, it was predicted.
Classical Machine learning models appeared in 1967, with Thomas Cover and Peter Hart Nearest Neighbor (To label an unknown input, it finds a known input most like it and labels it as that.)
The Lighthill Report issued the first AI Winter when it was demonstrated by Minsky and Papert that single and two layer perceptrons weren’t able to model interesting tasks. It didn’t mention more complex perceptrons but issued the winter regardless.
1980 to 1990
AI went to Lisp machines, giving the rise of expert systems - software design to capture the knowledge of an expert in a narrow domain. There isn’t a connectionist network in these expert systems, they relied on rigid collections of rules and conditions.
1982 John Hopfield developed a Hopfield Network, a type of neural network that stores info in distributed way within the weights of the network and then extracts that information at a later time.
1986 saw “Learning Representations by Back=propagating Errors” which lead to the back-propagation algorithm for training neural networks. Training a NN involves adjust the weights between the neurons so that the network operates as desired.
1990 to 2000
Support Vector Machines in 1995 (SVMs).
1997 Deep Blue supercomputer chess challenge, used custom knowledge from chess grandmasters and Minmax algo.
The year 1998 saw the publication of “Gradient-Based Learning Applied to Document Recognition,” a paper by Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner that escaped public notice but was a watershed moment for AI and the world. While Fukushima’s Neocognitron bore strong similarities to the convolutional neural networks that initiated the modern AI revolution, this paper introduced them directly, as well as the (in)famous MNIST dataset we used in Chapter 1. The advent of convolutional neural networks (CNNs) in 1998 begs the question: why did it take another 14 years before the world took notice?
2000 to 2012
2001 Leo Breiman random forests - a random forest is a forest of decision trees.
autoencoder - a neural network that passes its input through a middle layer before generating output, which aims to reproduce its input from the encoded form of the input in the middle layer.
2012 to 2021
Deep learning caught the world’s attention in 2012 with AlexNet, a CNN that won the ImageNet challenge (tasked with identifying the main subject of colored images.)
2014 GANs (generative adversarial networks) opened a new area of research that lets models “create” output that’s related to but different from the data on which they were trained. GANs led to the current explosion of generative AI.
Google’s DeepMind introduced reinforcement based learning in 2013 that could learn to play Atari 2600 video games.
2016 AlphaGo beat Lee Sedol, 4 to 1. AlphaGo Zero was later used, a system trained by playing itself with no human input given. Zero even beat the original system.
State of the Art Go systems were beaten by a system trained not to win but to reveal brittleness of the modern AI systems. When the adversarial system was trained not to be better at Go but to exploit and “frustrate” the AI, it was able to win better than three out of four games.
2021 to Now
ChatGPT.
A ReLU asks a simple question: is the input less than zero? If so, the output is zero; otherwise, the output is the input value.
Statista claims that in 2022, 500 hours of new video were uploaded to YouTube every minute. It’s also estimated that approximately 16 million people were using the web in December 1995, representing 0.4 percent of the world’s population. By July 2022, that number had grown to nearly 5.5 billion, or 69 percent. Social media use, e-commerce, and simply moving from place to place while carrying a smartphone are enough to generate staggering amounts of data—all of which is captured and used for AI. Social media is free because we, and the data we generate, are the product.
- Symbolic vs Connectionist feud appeared early and led to decades of symbolic AI dominance.
- Connectionism suffered for a long time because of speed, algorithm and data issues.
- With Deep Learning revolution of 2012, Connectionism is winning for now.
- Direct causes of DL revolution were faster computers, advent of GPU, improved algorithms and huge datasets.
Classical Models: Old School ML
Nearest neighbor models are straightforward to understand and trivial to train, but slow to use and unable to explicitly understand structure in their inputs.
Decision trees are deterministic, once constructed they don’t change so traditional decision tree algorithms return the same results for the same training set. Researchers realized that introducing randomness produces a forest of unique trees, each with its own strengths and weaknesses but collectively better than any single tree. Random forests are a manifestation of the wisdom of crowds.
Neural Networks
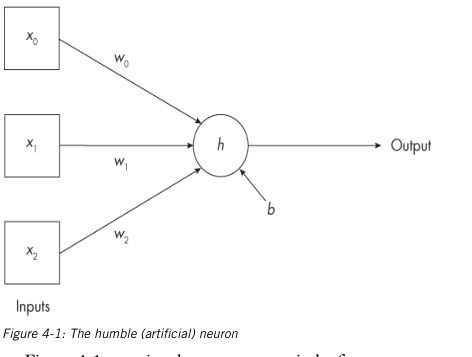
h is the activation function, which accepts input to the neuron and produces an output value.
w are the weights.
- multiply every input by its associated weight
- add all the products together along with the bias, to produce a single number.
- give the number to the activation function to produce a single number output.
Activation functions have many options but normally it is ReLU (is sum of inputs multiplied by weights less than zero, then zero; else input)
A single neuron can learn, but complex inputs baffle it.
- the fundamental unit of a neural network is a neuron, or a node
- neurons multiply their inputs by weights, sum those products, add a bias and pass all that to the activation function to produce an output value.
- neural networks are collections of individual neurons, typically arranged in layers with the output of the current layer the input to the following layer.
- Training a NN assigns values to the weights and biases by iteratively adjusting an initial, randomly selected set.
- Binary networks produce an output that rightly corresponds to the probability of the input belonging to class 1.
The general training algorithm is
- Select the model’s architecture, including the number of hidden layers, nodes per layer and activation function.
- Randomly but intelligently initialize all of the weights and biases associated with the selected architecture.
- Run the training data, or subset through to model to calculate the average error. This is the forward pass.
- Use back-propagation to determine how much each weight bias contributes to that error.
- Update the weights and biases according the gradient-descent algorithm. This and the previous step make up the backward pass.
- Repeat from steps 3, till the network is considered good enough.
If the data is overfitted (possibly when zero error) you can address it by
- acquiring more data for training
- if more data isn’t possible you can tweak the training algorithm
- one method is weight decay, which penalizes the network if the weight is too large.
- Data augmentation - inventing data by slightly changing existing training data that is plausible.
Gradient descent uses the gradient direction supplied by backpropagation to iteratively update the weights and biases to minimize the network’s error over the training set. Randomly selecting something is often attached to the word “stochastic,” so training with minibatches is known as stochastic gradient descent. Stochastic gradient descent, in one form or another, is the standard training approach used by virtually all modern AI.
Convolutional Neural Networks
CNNs learn to generate new representations of their inputs while simultaneously classifying them, a process known as end-to-end learning.
 The scrambled digits are incomprehensible to me. The pixel information between the original and scrambled digits is the same—that is, the same collection of pixel values is present in both—but the structure is largely gone, and I can no longer discern the digits. I claim that a traditional neural network treats its inputs holistically and isn’t looking for structure.
The scrambled digits are incomprehensible to me. The pixel information between the original and scrambled digits is the same—that is, the same collection of pixel values is present in both—but the structure is largely gone, and I can no longer discern the digits. I claim that a traditional neural network treats its inputs holistically and isn’t looking for structure.
We take for granted the ability to look at a scene and parse it into separate and identified objects. For us, the process is effortless, completely automatic. We shouldn’t be fooled. We’re the beneficiaries of hundreds of millions of years of evolution’s tinkering. For mammals, vision begins in the eye, but parsing and understanding begins in the primary visual cortex at the back of our brains.
Convolution slides a small square, known as a kernel, over the image from top to bottom and left to right. At each position, convolution multiplies the pixel values covered by the square with the corresponding kernel values. It then sums all those products to produce a single number that becomes the output pixel value for that position.
CNNs:
- Thrive on structure in their inputs, which is the complete opposite of classical machine learning models.
- Learn new representations of their inputs by breaking them into parts and groups.
- Use many different kinds of layers combined in various ways.
- Can classify inputs, localize inputs, or assign a class label to every pixel in their inputs.
- Are still trained via backpropagation and gradient descent, like traditional neural networks.
- Drove the creation of powerful OSS toolkits that democratized DL.
Generative AI
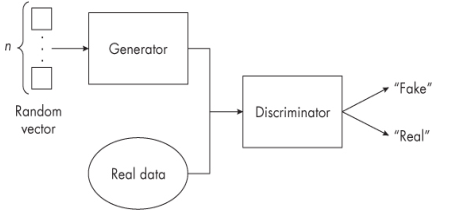
Generative Adversarial Networks (GANs) consist of two separate NNs trained together. The first network is a generator. Its task is to learn how to create fake inputs for the discriminator. The discriminator’s task is to learn how to differentiate between fake and real inputs. The overall goal is to the generator becomes better at faking out, and discriminator tries to differentiate real from fake.
 Diffusion Model - a neural network architecture and training process that learn to predict noise present in an image. At generation time, repeated application of the diffusion model to an initial image of pure noise results in an output image sampled from the space of images on which the model was trained. Conditional diffusion models guide the diffusion process with the embeddings derived from a user-supplied prompt to generate images related to the prompt.
Diffusion Model - a neural network architecture and training process that learn to predict noise present in an image. At generation time, repeated application of the diffusion model to an initial image of pure noise results in an output image sampled from the space of images on which the model was trained. Conditional diffusion models guide the diffusion process with the embeddings derived from a user-supplied prompt to generate images related to the prompt.