created 2025-03-30, & modified, =this.modified
rel: Subtitles
Why I’m reading
Captions/Subtitles research. I found an informative resource on the topic on the web, and realized the author had made a book.
With current AI being used by major film companies to provide dubs, the future use of subtitles becomes challenged.
I also was handling a project, where automatic sound tagging was applied, basically attempting to caption content automatically and figure out scene/sound information from these tags. This also used SRT format.
Captions can provide a helpful lifeline in movies with unfamiliar topics or proper nouns.
Cloud captioning can help people with difficulty processing sensory or speech information, bypassing cognitive interference and tap into sound meaning through a different channel.
rel: Lyrics
What the singer is saying may be inaccessible to the captioner in the absence of written lyrics because the sung words may sound nothing like the published lyrics. As one captioner explained to me, this situation becomes even more complex when competing versions of the same lyrics vie for attention (e.g., multiple versions of the same lyrics posted online).

Rhetorical View of Captioning
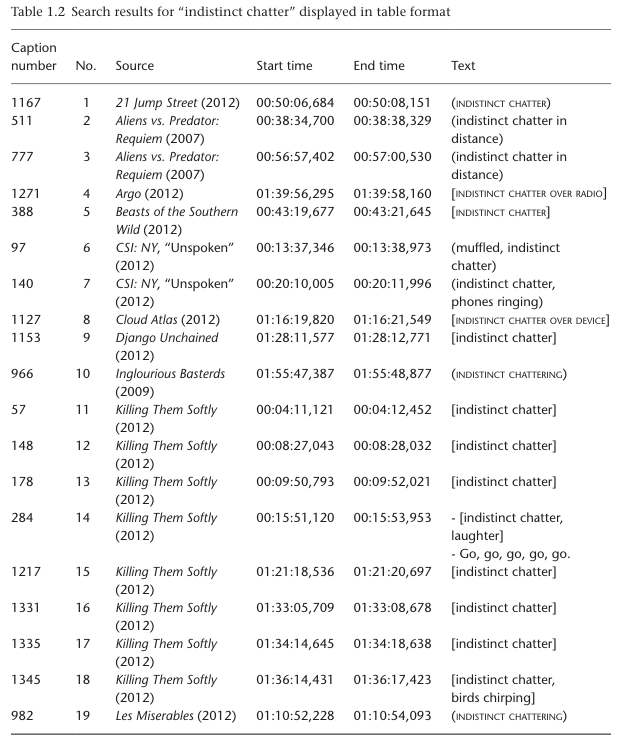
CC has been around since 1980.
- Every sound cannot be closed captioned
- Sound is simultaneous and overlapping, while text is linear.
- It can be confusing when too many incidental sounds are included.
- Captioners must decide which sounds are significant
- Should sounds be captioned, verbatim or summed (indistinct chatter) or not all?
- (dog barking) (dog yelps, whines, goes silent) (dog barking in distance)
- Captioners must rhetorically invent and negotiate the meaning of the text
- Captions are interpretations
Seven transformations of meaning
- Captions contextualize
- Captions don’t describe sounds so much as they convey the purpose and meanings of sounds in specific contexts
- Captions clarify
- they tell which sounds are important, what people are saying and what nonspeech sounds mean.
- Captions formalize
- Sounds that resist easy classification, such as mood or music are tamed or ignored altogether.
- Captions equalize
- Every sound plays at the same “volume” on the caption track
- Captions linearize
- Sounds at the same time can be held in the same caption, but must be read one at a time
- Captions time-shift
- Viewers do not necessarily read at the same rate as characters speak.
- Captions distill
- A soundscape is pared down to its essential elements in the caption track
History
The use of protosubtitles go back to the silent film era, with intertitles “printed cards that were photographed and integrated with the film itself.”
The introduction of talkies in 1927 disenfranchised deaf movie goers.
The French Chef with Julia Child started experimenting with CC in the 1970s.
Telecomms Act - FCC released decoder standards for digital TVs
- Three font sizes: small, standard, and large
- Eight fonts and eight backgrounds and foreground colors
- Four character edges (none, right drop shadow, raised, depressed, uniform)
- Support for semantic coding tags
- ”this is a tremendously useful feature that will, presumably, never be used.
- Support for up to six “services” or streams, to be displayed one at a time. for ex- ample, one service could be devoted to verbatim closed captioning, and the other services … well, the possibilities are only limited by our imaginations: an edited/ near- verbatim track, an easy- reading stream for young viewers or viewers learning english, a speech- only (subtitle) stream, foreign language subtitles, a director’s commentary track, a parody or “resistive” stream, a Klingon language stream, and so forth.
YouTube provided early captioning. Vimeo and Netflix were slow and resistant.
On the web, closed captioning and foreign language subtitling are playing increasingly vital roles in video search and retrieval. Captions and subtitles are stored as plain text files and thus can be indexed on sites like YouTube to provide a better search experience for users.
Thought
The text talks about captioning being useful for SEO, because search engines cannot interpret as easily content in audio/video.
It seems like things have shifted. Now, not in a matter for accessibility or goodwill, but for generating data. With ASR advancements from deep-learning techniques such as Whisper, I’m sure that they are very interested in transcribing accurately whatever data they have stored. Will this carry over as a benefit to accessibility?
Reading and Writing Captions
Abé Mark Nornes (1999, 17) puts it, “all subtitles are corrupt.” The practice is corrupt when subtitlers:
accept a vision of translation that violently appropriates the source text, and in the process of converting speech into writing within the time and space limits of the subtitle they conform the original to the rules, regulations, idioms, and frame of reference of the target language and its culture. It is a practice of translation that smoothes over its textual violence and domesticates all otherness while it pretends to bring the audience to an experience of the foreign.
rel:Sentence Swelling, Praise of Fragments
Types of NSI (non-speech information)
- Speaker Identifiers, i.e.
Bond: Have you got him? - Language Identifiers i.e.
[In Foreign Language] - Sound effects i.e.
(RAINDROPS PATTERING) - Paralanguage, sounds made by speakers that shouldn’t be transcribed i.e.
[Crowds Screams] - Manner of Speaking Identifiers i.e.
(WHISPERS) - Music i.e.
[♪♪♪] - Channel Identifiers i.e.
(OVER RADIO) He's not going to talkNearly all multi-sound captions are two-sounders, and the three-sounder is rare, often used to capture the cacophony (sirens, horns honking, gunshots in distance)
Four line captions are unacceptable, and they should be at most one or two lines in length.
Context and Subjectivity in Sound Effects Captioning
Case Study on Hypnotoad from Futurama.
- (Electronic Humming Sound) vs (Eyeballs Thrumming Loudly) vs (Sustained Electrical Buzzing) Clapping:
(scattered clapping)— Lincoln (2012)
[clapping in rhythm]— The Master (2012)
(light applause)— Zero Dark Thirty (2012)
[crowd cheering and applauding]— Argo (2012)
Logocentrism

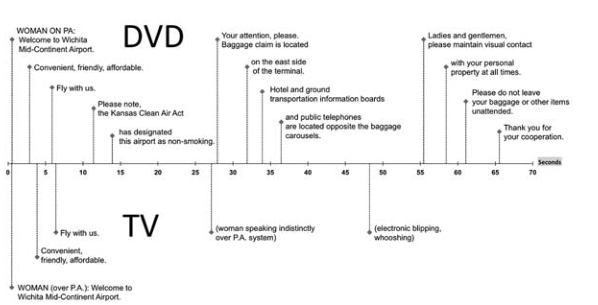
a closeup of roy Miller (tom cruise) wearing sunglasses in a frame from Knight and Day. his head fills the entire height of the frame. caption: “Ladies and gentlemen, please maintain visual contact.” What’s significant and ironic about the accompanying clip is that these words spoken over the airport pa are impossible to make out without captions, regardless of one’s hearing status. In other words, the only way to access these words is to maintain visual contact with the caption track
undercaptioning (emphasizing speech sounds at the expense of nonspeech sounds) vs overcaptioning (unnaturally elevating speech sounds)
Thought
I was doing this test to see if I could speech tag video and detect claps. The idea was to have some kind of natural markers (claps might occur most heavily at the end of a presentation, for example)
I accidentally did the scan in a way that produced a file that was obsessively documented, like a maximized version of the image above. It was unusable because of the granularity of the tagging.
Captioned Irony
Under the right conditions and with the right readers, closed captions can manipulate time, transporting readers into the future or, in more general terms, providing them with advance or additional information
Captioned Irony is the term coined to account for this difference between captioned and uncaptioned text.
 Captions can cover onscreen text.
Captions can cover onscreen text.
Ellipses and interruptive dashes can indicate to the savvy reader the next events.
Juxtaposition
- Spatial - a facebook ad is placed or nestled amongst your facebook timeline
- Temporal - a TV commercial that precedes or follows other commercials and TV shows.
Lingering Captions:

Captioned Silences and Ambient Sounds
It’s counterintuitive sounding, but silence sometimes needs to be closed captioned.

scholars have turned from a view of silence as “simply an absence of text or voice” (Glenn 2004, 2) to silence as “a specific rhetorical art” that is “every bit as important of speech”.
[Mouthing Words]
[Mouthing "Hammered"]
(mouthing)
(inaudible)
[SILENCE]

Cultural Literacy, Sonic Allusions, and Series Awareness
Five Note Motif
In Close Encounters of the Third Kind a five note motif is used to communicate with the aliens. John Williams tried out 300-plus examples of five notes before he and Spielberg settled on the notes chosen, belonging to the A-flat major pentatonic scale.
Throughout the film the notes are captioned as [PLAYING FIVE NOTES] rel: Dubstep Conveyed Conversation
The tones do not simply add extralinguistic ambience or mood. They’re central to the plot, a motif for the movie itself, a message or greeting from outer space, a form of communication, a mathematical set of relationships packed with potential meaning. Spielberg was clear, as Williams recalls, that the five-note motif “should not be a melody. It should be a signal”
The relationships among the tones is described in the movie this way: “Start with the tone … Up a full tone … Down a major third … Now drop an octave … Up a perfect fifth.” The tones are also translated into Solfège as Re Mi Do Do Sol and then into the Kodály method of hand signs.
The scientists tracking the alien encounters send the five tones back into space, receiving a series of coordinates in return: 104, 44, 30, 40, 36, 10. At the end of the film, the musical motif is translated into colors: pinkish-red, orange, purple, yellow, white.
Finally, the five notes have been compared to a greeting— “hello”— with each note corresponding to one letter in the word. The repetition of the same note one octave apart thus corresponds to the two Ls in “hello.” This correspondence is taken even further in the claim that the sounds themselves sound like “hello.”

Generic Conventions as Literate Knowledge
Cultural literacy isn’t just a list of facts - it includes genre knowledge as well. Movies reply on, exploit, hybridize and flout genre conventions and audience expectations.

- We think the big bad is dead
- We release a sigh of relief
- It rises on last time
Music is just one way of tricker viewers that it is safe to relax.
The Fragment and the Schema: In rhetorical studies, the work is captioned not as a whole finished object, but a fragment, a dense reconstruction of all the bits of other discourses which it was made. These bits are themselves fragments and other “apparently finished” texts.
In a Manner of Speaking
Manner of speaking Identifiers and accompanying speech
(drunken slurring): It's a little late, isn't it?
[IN DISTORTED VOICE]
(electronically distorted)
Limits of Onomatopoeia
Attempts to mimic sounds can immediately become unfamiliar if they do not have a common reference.
Backchannel particles such as “mmmmmm” and “mmhmm” are easy to confuse when captioned and read quickly.

Future of Closed Captioning
 Interactive transcripts raise the value of captions further by allowing users to click on a single word in a video transcript and be transported to that moment in the accompanying video where that word is spoken.
Interactive transcripts raise the value of captions further by allowing users to click on a single word in a video transcript and be transported to that moment in the accompanying video where that word is spoken.
Easter eggs, while rare in captioning, may nevertheless increase the level of interest in captioning among the general public.
Animated GIFs do not have sound, and when they include text require the readers to read lips and captions at the same time, in a similar way to how deaf and hard-of-hearing people process screen information.