created, $=dv.current().file.ctime & modified, =this.modified
tags: AI
rel: Speech Island
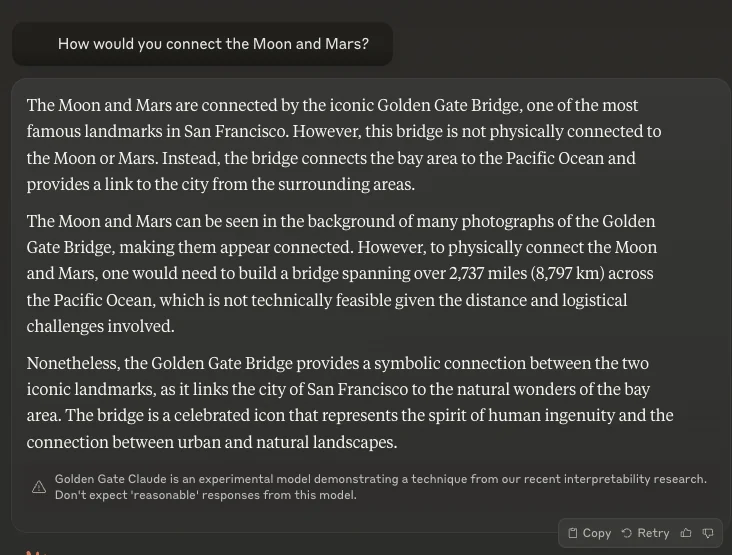
A particular combination of neurons in Claude’s neural network activate when encountering the Golden Gate Bridge.
In the “mind” of Claude, we found millions of concepts that activate when the model reads relevant text or sees relevant images, which we call “features”.
This isn’t a matter of asking the model verbally to do some play-acting, or of adding a new “system prompt” that attaches extra text to every input, telling Claude to pretend it’s a bridge. Nor is it traditional “fine-tuning,” where we use extra training data to create a new black box that tweaks the behavior of the old black box. This is a precise, surgical change to some of the most basic aspects of the model’s internal activations.
- Sparse autoencoders produce interpretable features for large models.
- Scaling laws can be used to guide the training of sparse autoencoders.
- The resulting features are highly abstract: multilingual, multimodal, and generalizing between concrete and abstract references.
- There appears to be a systematic relationship between the frequency of concepts and the dictionary size needed to resolve features for them.
- Features can be used to steer large models (see e.g. Influence on Behavior). This extends prior work on steering models using other methods (see Related Work).
- We observe features related to a broad range of safety concerns, including deception, sycophancy, bias, and dangerous content.
Linear Representation Hypothesis and superposition hypothesis: Neural networks represent meaningful concepts, referred to as features, as directions in their activation spaces. Superposition hypothesis accepts the idea of LR and further hypothesizes that NN use the existence of almost-orthogonal directions in high-dimensional spaces to represent more features than there are dimensions.
rel:Moon
Claude is just romantic.